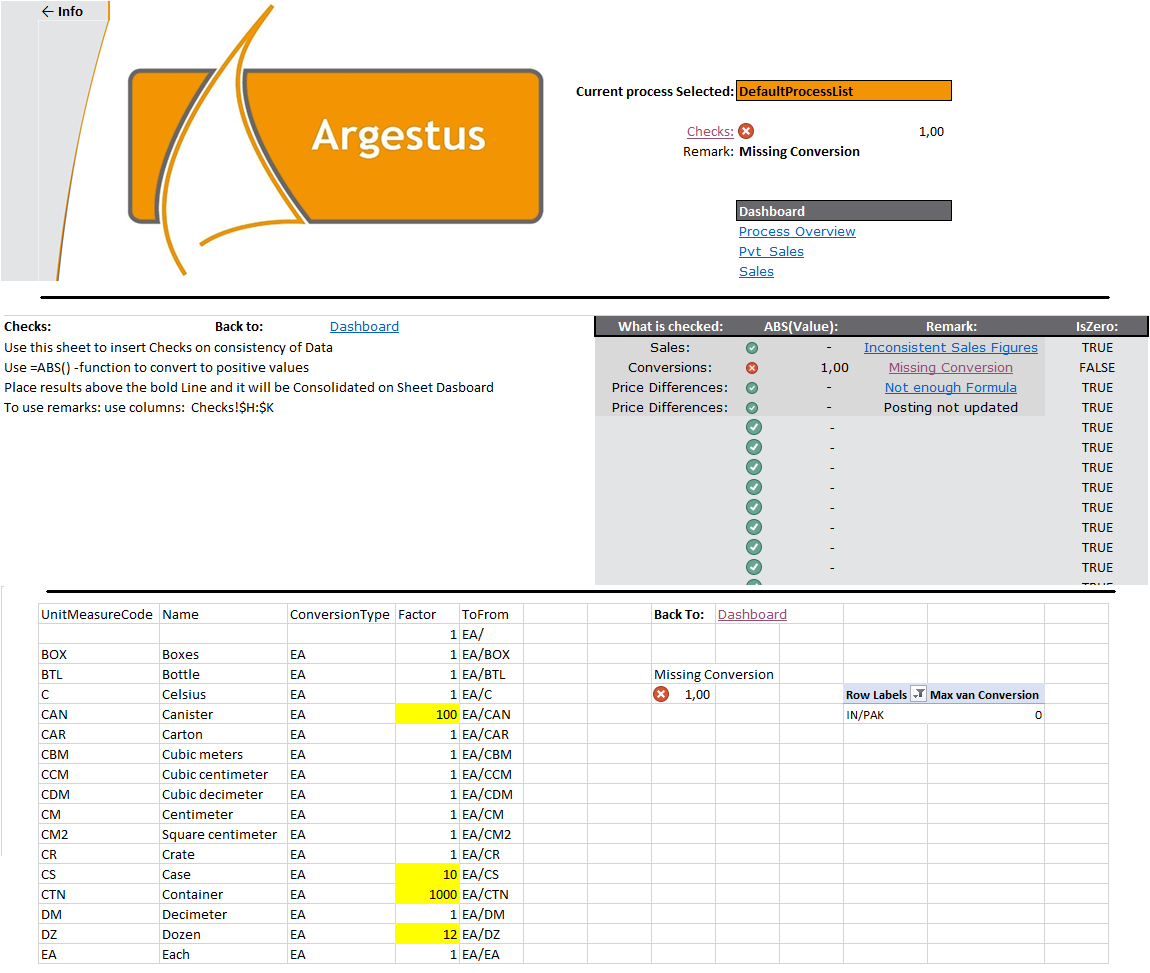
Data Quality
Data integrity checks can be specified to catch unexpected data. This means that any number of checks can be build in to prevent likely to highly unlikely changes/errors in input or output data. A good example occurred a while ago. One of the checks build in a model was made for a situation which ‘could not occur’. But with Murphy’s Law in the back of my mind, the check was build in anyway. A simple addition to the process, made within minutes. And what do you know, some months later the situation which presumably could not occur, did occur! The build in check resulted in a warning and prevented an error which probably nobody would have noticed because it just ‘could not happen’!
Think by yourself: Could you estimate your ‘first time right’ track-record? And what would you want it to be?